Workflows - 3 Levels of Complexity
Watch post below, or listen on podcast app under Gregory Schmidt
As healthcare realizes that improved outcomes and reduced cost are associated with processes that decrease variability, more ‘workflows’ will be introduced.
Note: for these examples, the ‘workflow’ will be a questionnaire. However, a ‘workflow’ can be any other type of process, and much more complicated than a questionnaire. Some other workflow examples are mentioned in Part 2.
Part 1:
Levels of Workflow Integration
Let us start with a ‘simple’ workflow, and add further complexity over four levels.
Level 1: Separate workflows
This is pretty straightforward. We see this workflow on paper forms all the time.
eg. Person-1 completes a questionnaire, that is then reviewed by Person-2: anurse completes a pre-clinic questionnaire that is then reviewed by the physician, or the pharmacist has a medication education session with the patient, and documents this on a form that is then viewed by the clinic nurse.
eg. The second clinician then completes their own workflow. After reviewing a questionnaire completed by the community health worker, the nurse then completes his own workflow (‘questionnaire’).
Note: at this level the workflow (questionnaires in this case), are entirely disconnected between users. Each user has their own ‘workflow’, and has to ‘hand-off’ to the next user.
Level 2: Simple Task Shifting: one workflow across multiple users
In level two, multiple users can contribute to a single workflow.
We continue to use the workflow example of a clinical questionnaire. In Level 2, information collected by users in separate forms, can feed forward into the next form.
eg. A patient is seen for follow up in a hypertension clinic. The patient is always first seen by the nurse, and then the physician. The nurse completes an intake questionnaire and exam. This information is then fed to the physician’s encounter form.
Level 2 also includes the ability of a form to auto-populate based on historical information found elsewhere in the patient chart. (ie. information other than that was collected by the previous user).
Some unresolved administrative issue remain with feeding forward information, regarding responsibility for signing off data. This is discussed in the footnotes.
It is important to remember that the patient can be a part of the workflow. They can complete questionnaires, longitudinal symptom reporting, and patient generated biometric data.
Level 3: Dynamic task shifting: workflow allocation adapts to environment
In Level 2, the steps within a workflow are set-in-stone. In Level 3, the workflow steps are divided automatically based on resources available.
eg. Consider a workflow that involves Section A/B/C/D.
If only a physician is in-clinic, they will be prompted to complete sections A/C/D. (In this case B is considered not something the clinician ever has to complete).
If the nurse is also in clinic, they will complete sections A/D, and the physician will complete section C.
When the community health volunteer is also present, they will complete section A. The nurse will complete section D. The physician complete section C.
If a nutritionist is available, they will complete section B.
In this manner. The system needs to know (a) which users are present, and (b) how to divide the workflow based on who is available.
In the simple version of dynamic task shifting, I see the workflow division occurring at the start of the clinic. The system will then know for instance (a) what workflow is being used for the patient, and (b) which users are present that day. It then allocates workflow steps based on that.
In the advanced version of dynamic task shifting, the system can allocate work in real time. For instance, if a backlogs occurs with the pharmacist, some of the pharmacist’s work may shift to the nurse (provided those workflow steps [eg. in this case ‘questions’] have been coded as transferable across both users]
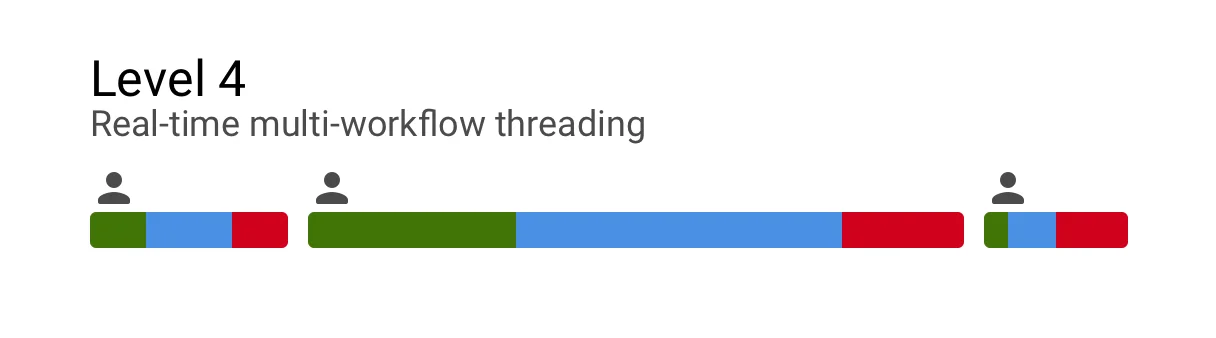
Level 4: Real-time multi-workflow threading
Level four builds upon the previous levels by integrating multiple workflows into one.
eg1. Patient is to be seen for both diabetes and hypertension. Each issue has their own workflow. In Level 4 functionality, both the diabetes workflow and hypertension are integrated into a single workflow. The workflow steps are then (a) assigned and (b) workload balanced in real time using Level 3 dynamic task shifting.
* Workflow steps that are the same between both workflows are eliminated. Such as duplicate questions.
* Workflow steps are threaded together in a rational sequence.
eg. The blood pressure (for hypertension workflow), and the finger prick blood glucose (for diabetes workflow), are sequenced in proximity together within the nurses workflow.
eg. When the clinician is reviewing the hypertension medication side effects; they are then prompted to review the diabetes medication side effects.
In the basic version, the workflow integration occurs prior to the visit, in part directed via a pre-clinic questionnaire / pre-selected at the previous clinical encounter / or via pre-clinic clinician triage.
In advanced versions, the system can integrate additional workflows while the patient is in the middle of an existing workflow integration.
For instance - if it is discovered that a patient also has arthralgias, the workflow around this can be added in the middle of a Hypertension+Diabetes appointment.
When a new workflow needs to be added in the middle of a previous workflow integration, there are two approaches. One is to assign the workflow tasks across all users in a workflow (this may require the patient to ‘go-back’ to a user they have already seen. The second option is to assign the new workflow steps to users the patient has not yet seen (eg. ‘down-stream users). Perhaps the decision can be semi-automated based on the burden of additional workflow steps that workflow integration adds.
Part 2:
Complexity in Workflows
Part 1 presented a way to take a workflow, divide it among the available resources, and then integrate multiple workflows together.
There are many ways to make workflows far more complicated. For instance,
A) Indicate when all the resources required for a workflow, or when the next workflow step, is ready
One step in a workflow may be a set of lab results, or imaging reports. These results may be required before the patient can have an appointment books, or before they can proceed within an appointment from assessment to treatment.
The workflow system must know when the next steps can proceed, and provide alerts when there are delays.
B) System timing based on anticipated workflow length
The estimated total duration of a workflow an be estimated, based on the number of workflows to be integrated, and resources available to carry through the workflow. This can help provide more accurate estimates for workflow duration and timing - such as booking an appointment.
C) Advanced Load balancing
The system dynamically load balances workflows. Simply moving questionnaires between users is just the start. You can imagine the system also load balancing patient’s pathways through clinic based on capacity at the lab, or imaging, or reception.
D) Clinical decision support
Replace steps in the workflow that require clinician prediction and interpretation of data, with algorithms.
Footnote: On Data Provisioning and which version of data elements to display
How is data ‘signed-off’. For instance. If a community health volunteer completes an intake form, and this information is fed into the physician form, who is responsible for the ‘final version’ of this information?
If this information populates the physician form, when they sign off on it, does it mean they are ‘responsible’ for its validity?
In some cases, the fed-forward information may be crucial information to the physician, and they did verify that information. In other cases the auto-fed information may be of little clinical utility and they did not even read it.
When a user ‘down-stream’ updates information that was collected by someone previously, what happens to the previous information? Is it visually ‘replaced’, is it ‘kept as an old answer’ and do we display all old answer, the most recent ones, the ones that are different? What responsibility does the person who entered the original data have? What if in fact they were correct, and the person who updated their data incorrect?
And finally, from a reporting perspective, which set of data do we use for reporting? The ‘final-person’ in the workflow? Does their ‘version’ of the document reflect final reality? What is someone earlier in the workflow updates the result of one of their fields?
Which set of data is used for analytics purposes?
Anyway, lots to resolve here, more it is more an issue of administration, than one of technical limitations.
Some of these questions are addressed in my piece: Manage auto-populated EHR data separately