ICD-10 Coding Using Machine Learning
Summary
Complete and accurate ICD data is important. These medical identification codes form the backbone of administrative data sets and are used for international epidimiologic work, a significant number of research studies, and billing.
Current electronic medical records have modules to manually enter ICD codes. These modules are incredibly cumbersome and lead to poor quality coding.
EHR's should integrate directly into their software computer-assisted coding using natural language processing and machine learning. This will improve the quality of ICD coding.
This article traces the history of clinical auto-coding, and why it is more important than ever to integrate computer assistance.
-----------------------------
Article Overview:
Part 1: History of Computer Assisted ICD Coding
- History of ICD Codes
- A Numbers Problem
- ICD Coding: Paper Charts
- Clinical Auto-Coding (CAC): Early Days
- Next Generation CAC: Natural Language Processing
- Current CAC ICD Software
Part 2: Future Work
- Integrating Computer-Assisted Coding into the EHR
-----------------------------
Part 1: History of Computer Assisted ICD Coding
History of ICD Codes
ICD Codes - International Statistical Classification of Disease and Related Health Problems - were first developed by the World Health Organization in 1893. Initially used to track the cause of death, today ICD codes are used by many hospitals to document admission diagnosis and coordinate payments.
ICD codes form the bulk of administrative data sets. Many research studies use administrative data sets - having complete and accurate data is essential.
A Numbers Problem
Implementing and upgrading to new versions of ICD is a massive undertaking. Despite the most recent ICD-10 coding system being completed in 1994, the United States has only upgraded within the last year from their ICD-9 system (originally implemented in 1977).
Each edition of ICD brings greater number of codes. ICD-10 has over 16,000 codes. The United States has two additional ICD systems: ICD-10 Clinical Modification - 69,833 codes, and ICD-10 Procedure Coding System - 71,918 codes. Some of these are pretty specific.
Relying on manual human entry of such codes is impractical from a time constraint, and unprofitable from lost revenue of incorrectly coded admissions.
The 160,000 ICD-10 codes are a perfect problem for natural language processing (NLP) and machine learning.

I. ICD Coding: Paper Charts
Paper based hospitals rely on large teams of 'human coders'. Coders read medical records on discharge and record what ICD codes occurred.
Physicians may start the coding process by writing down the diagnosis and comorbidities that occurred in hospital. However, this preliminary list is often incomplete and it requires the coder's diligence in reading the records in depth to collect all ICD codes.
The majority of hospitals in North America still use paper charts. Therefore ICD coding by hand is dominant.
II. Clinical Auto-Coding (CAC): Early Days
Introduction of electronic health records (EHRs) enabled the introduction of Clinical Auto-Coding (CAC).
CAC is the use of computers to generate lists of potential clinical ICD codes. These potential codes are presented to a human 'coder' for review and validation.
CAC software has been around since the late 1990s and evolved over the years. In many ways such software has become more robust as more of the medical record is digitized. CAC software now can 'read through' and integrate free text from clinic notes, problem lists, procedures, lab tests, and imaging reports.
A second big advantage of CAC software that it often pulls together these different systems into one screen. This saves the coder from having to log into a dozen different medical record system to gather data on a single patient (and having the systems time out on the coder, when they using another window).
CAC for many years used two more basic methods of identifying ICD codes: Dictionary Matching and Pattern Matching. These systems search for direct matches to keywords or clusters of keywords to identify ICD codes.
The obvious downside to this matching system is that it may generate many codes not relevant to the patient's care - creating poor specificity. Similarly it may miss issues that did not use the specific 'keywords' - creating poor sensitivity.
Example of Clinical Auto Coding interface. showing matched terms for coder verification. Watch full video here
III. Next Generation Clinical Auto-Coding: NLP
CAC has the potential to undergo a huge advancement with the introduction of Natural Language Processing (NLP). NLP enables the computer to do more than identify matched words and word patterns. NLP enables advanced understanding of meaning and intent. This breakthrough greatly improves precision.
Over the last five years there are multiple academic papers on the subject. They are unintelligible to anyone without an advanced statistical background. (I think) they overall appear to support the application of natural language processing - via machine learning to this problem. A list of these papers is included at the bottom of article.
3M has an excellent short white-paper on the subject of NLP & CAC. (download here). Highly recommend for anyone who is interested in the subject. Optum360 also has several papers.

** Download 3M white-paper **

Download Optum 360 white-paper

Download second Optum 360 white-paper
Current NLP ICD-10 Software
This is a short list of CAC companies. If anyone has additional companies, or knows in more depth the level of sophistication these packages offer please let me know.
Full disclosure: I have neither personally used any CAC software, nor actually know how good any of this software is. They all claim to use NLP, but I am skeptical how advanced they are.
Part 2: Future Work
Integrating Computer-Assisted Coding into the EHR
Aside from introducing more sophisticated NLP to ICD coding, work is needed to integrate computer-assisted coding into the EHR.
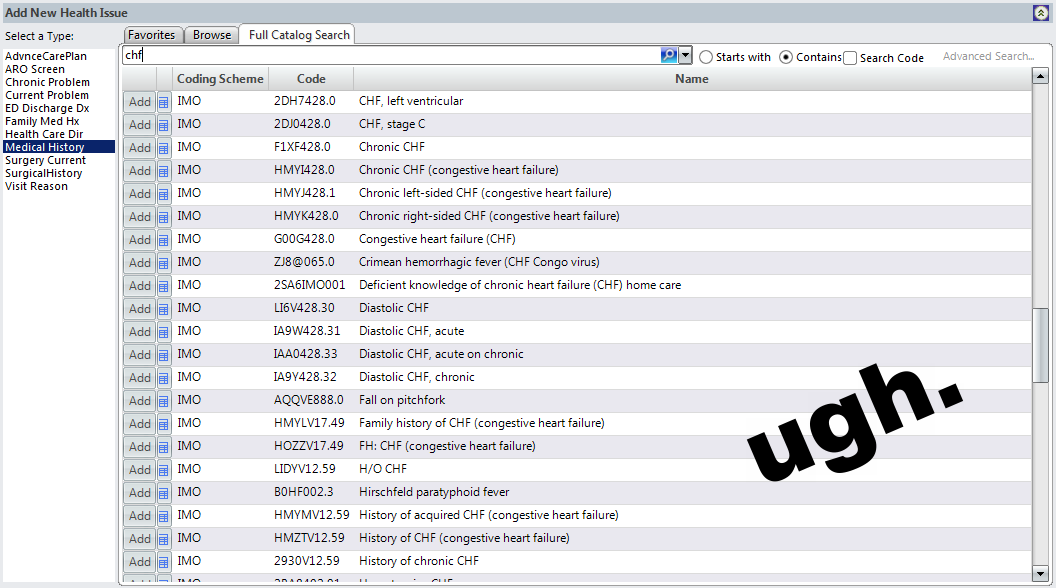
Current EHRs (such as EPIC and Allscripts) have ICD modules. In these modules clinicians select ICD codes at discharge from hospital. The user interfaces of these modules are one of the worst parts of the EHR. They are incredibly cumbersome.
ICD modules in EHRs do not use computer-assisted coding techniques - even though CAC has been available for over 30 years. Instead, users have to manually search for each code. The search feature is rather useless as many codes have the same keywords. As there are a number of ways to code the same presentation, there is incredible variation in coding.
Typical EHR - manual ICD code search
It is difficult enough to get physicians to write on a piece of paper a list of the patient's diagnosis and comorbidities on discharge. Forcing physicians to use terribly designed ICD coding modules in EHRs only increases frustration and reduces the chance ICD codes will actually be entered.
Our hospital asks physicians to enter at least one ICD code. Often they cannot actually find the one they want - usually because the the summary list of codes is too long to search through. Physicians will find one that looks 'kinda close', and then give up.
The next step in EHR development is incorporating third party clinical auto-coding solutions directly into the EHR. This way software would read the entire medical record and propose to the physician on discharge a summary list of ICD codes for review and validation. This saves the physician time in imputing the codes manual (which they do poorly), and reduces the processes of having a separate coding department to repeat the ICD entry.
Until EHRs integrate computer-assisted coding, GomberBlog has provided a more succinct coding system using Emoji icons.

More ICD emoji at Gomberblog
--GJS--
Notes:
Papers on Natural Language Processing / Machine Learning and ICD Coding
An article sumarising some research on NLP & ICD coding.
Impossible to understand papers on machine learning and ICD Coding:
Carroll, S. Automatic Code Assignment to Medical Text
Coffman, A. Wharton, N. Clinical Natural Language Processing Auto-Assigning ICD-9 Codes.

